According to the IDC, Big Data and analytics software and cloud services market reached $90 billion in 2021 and will more than double by 2026. A large part of these revenues are related to end-user query, reporting and analysis tools. With 80% of customers indicating they are more likely to do business with a company that offers personalized experiences, companies are more and more relying on our personal data to achieve this service personalization. This has prompted a never-ending data rat race amongst companies, on the belief that they need to harvest and maintain (personal) data themselves in silos. However, there have been increasing non-technical concerns about the hyper-centralization of personal data, substantiated by data scandals, e.g. Cambridge Analytica & Equifax. Companies performing data collection in silos are plagued by legal, economical, societal, and ethical barriers, e.g. GDPR. As such, a rapid paradigm shift can be noted towards decentralized storage of personal data, in which each person controls their own personal data pod(s), guarding all public and private data they or others create about them.
From a technical perspective, the data analytics effort thus shifts from processing a centralized very large data set, towards processing a very large number of small and individually permissioned data sets. Decentralized data is inherently varied, as there exists no central authority that can enforce one data format. The key to sustainability is that every data pod provider implements a universally accepted standard to share this data. So each service provider can also adopt this standard and thus request and process data from any data pod provider, with the person’s permission. The Solid specification has large potential of becoming this standard. Solid’s focus is to enable the discovery and sharing of information in a way that preserves privacy.
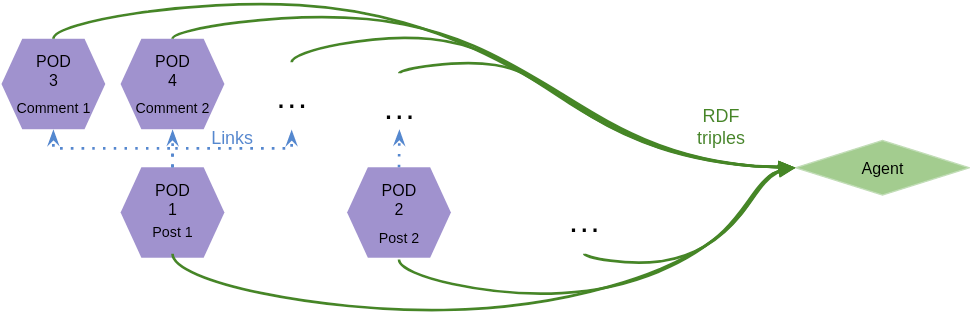
Solid is built upon existing (Semantic) Web standards, as each pod stores data in the form of documents containing Linked Data (RDF) to allow for high interoperability between services. The meta-data of the data contained in a pod is described using a schema, i.e. ontology, which makes clear how the data should be interpreted. While the community is currently gaining momentum and rapidly realizing decentralized solutions for the storage and querying of data in Solid pods, fundamental research questions arise from a service provisioning viewpoint concerning the scalable and performant processing of all the decentralized data.
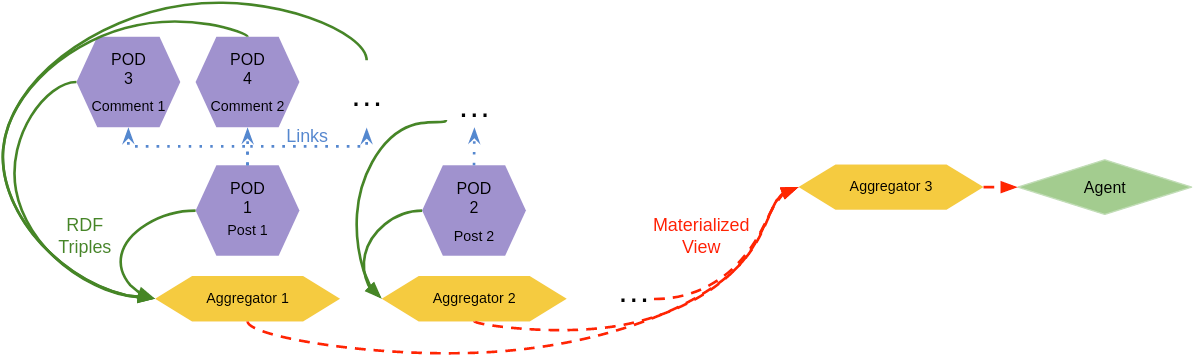
We can illustrate the challenges that arise through a hypothetical social media example. A social media site allows users to have posts with a topic. Users can also comment on these posts. Imagine subscribing to a topic and wanting to query all the posts with this topic and the comments on this post. All the posts and comments are in the pods of their respective author. This would therefore require the query engine to first locate all the pods and then fetch all the relevant data on these pods to then perform the query. This would quickly become infeasible to execute in acceptable time when scaled to the entire web. Moreover, as there is no centralized authority that imposes a particular schema to use, it is possible that the data in the different pods is represented using different ontologies, e.g. to enable interoperability with other tools. As such, schema/ontology alignment through semantic reasoning (automatically) or explicit schema mappings (manually) is required to map or link the data in the pods to each other, adding to the challenge of generating the query results in a timely manner.
As such, tackling the service information need in a decentralized pod environment requires solving a federated query and reasoning problem with a high number of independent and varied data sources, requiring more complex algorithms while having less computational power per node than centralized systems.
In this research we want to investigate whether these problems can be adressed by introducing aggregators into the Solid ecosystem. Aggregators are a network of query and reasoning agents, each of which contribute (partial) results to a query by providing an up-to-date, i.e. continuously maintained, view on the underlying decentralized data. A view in this case refers to query results where the results also include results from data originally modelled using different ontologies than the ones used in the query. By using aggregators, a service information need could be quickly resolved by just retrieving the result from one or more aggregators.
To realize this vision, the student can choose to focus on one or more of the following challenges:
- Incept an incremental query engine that is able to query decentralized sources in an efficient & scalable fashion.
- Ensure more complete query answers by enabling schema alignment across decentralized storage using different ontologies.
- Ensure scalability by enabling that the location & function of the aggregators can be discovered and combined easily
- Designing a proof-of-concept for aggregators within the Solid ecosystem within a particular use case, e.g. social media, but other use cases can be used that allign with the interests of the student