FRACTION: eFficient decentRAlized proCessing of high-velociTy streamIng data spread across heterogeneous persONal data vaults
Keywords: Artificial Intelligence, AI, Privacy, Semantic Web, Solid, Web, decentralization, reasoning, Scalability, Decentralized reasoning, Logic, Performance, Personal Data
Promotors: Femke Ongenae, Pieter Bonte
Students: max 2
Problem
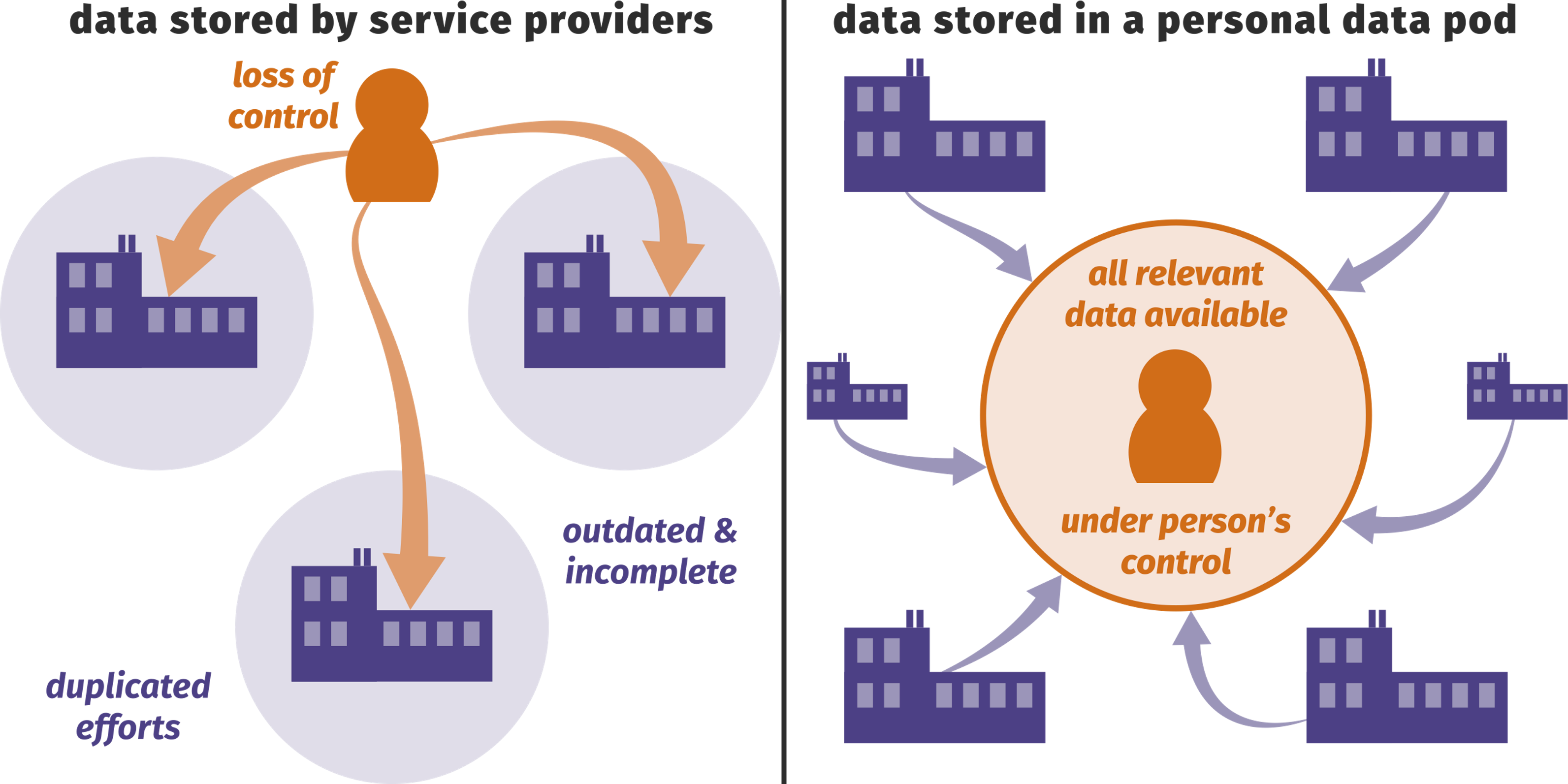
There are increasing concerns about the centralization of personal data that has resulted from over a decade of Big Data thinking, substantiated by data scandals, e.g. Cambridge Analytica. This instigates a paradigm shift toward decentralization of personal data. People must be able to control their own personal data vault, in which they guard all public and private data they or others create about them. These vaults allow individuals to decide at every moment to which people and organizations they selectively grant read or write access to specific documents. Companies can still use that data, without needing to collect or control it themselves, since they can ask permission to access the pieces of data. Data vaults are not limited to personal data. Sensors and companies can exploit the same storage principle.
From a technical perspective, the data analytics effort will thus shift from processing a centralized very large data set, towards processing a very large number of small and individually permissioned data sets. Moreover, decentralized data is inherently varied, as there exists no central agreement on data formats. As such the key to sustainability is that every data vault provider implements a universally accepted standard. As such each service provider can also adopt this standard and thus request and process data from any data pod provider, with the person’s permission. Solid provides a collection of standards and data formats/vocabularies that allow to set up data vaults that store data in the form of documents with the appropriate access control mechanisms, e.g. identity, authentication, permission lists, etc. In Solid each vault stores data in the form of documents containing Linked Data. Semantic Web reasoning techniques, exploiting the explicit semantics of Linked Data, can be employed to perform data analysis. Semantic Web schema/ontology alignment through reasoning is thus essential to decentralized data, as each vault is maintained individually, making it impossible for each data vault to use the same data format as in a centralized scenario. While the community is currently gaining momentum and rapidly realizing decentralized solutions for the storage and querying of data in personal vaults, fundamental research questions arise from a service provisioning viewpoint concerning the scalable and performant processing of all the decentralized data.
Within this thesis, we will look at this problem from a querying perspective: a service provider has an information need, expressed as a query, and wishes it to be answered. This requires solving a federated query and reasoning problem with a high number of independent and varied data sources, requiring more complex algorithms while having less computational power per node than centralized systems. Moreover, companies are increasingly dealing with high velocity streaming data, e.g. collected by sensors or social media streams. There is a need for research on exploiting data locality, processing data close to its production site in order to greatly reduce the amount of data that needs to be transmitted, such that we can achieve low-latency and high-velocity processing.
Goal
In this disseration, we want to address this problem by using a network of query and reasoning agents, each of which can be deployed on any network node and contributes partial results to a query. Processing nodes are heterogeneous, as they can have different processing resources and unpredictable network bandwidths. The solution will need to fully exploit data locality, processing the data close to the source.
The overall aim of the dissertation is to design performant, scalable and transparent Big Data semantic reasoning techniques across decentralized storage and processing nodes in order to pave the way towards realization of the decentralization vision in which every user, company or device stores their data in their own personal data vault. Decentralized Big Data can solve the problems of its centralized counterpart, however, the following four fundamental research objectives need to be addressed in the dissertation:
- Design of decentralized analytics that can autonomously distribute the data analytics across the data stored in the distributed processing nodes, while hiding the complexity of the network.
- Investigation of methodologies that exploit the heterogeneity of the decentralized network to achieve scalable and performant decentralized analytics, while maintaining its correctness.